Latest Projects: RubyDAS & TwitterBackup
My latest job (also a combination of bioinformatics & web-design) makes me use Python and Django – let’s just say I still need to acclimate to the changed framework. But I did some Ruby and Rails-stuff in the weeks before I started this position:
The first project is RubyDAS, which Alex Kalderimis and I started to work on during this year’s DAS-Workshop at the EBI. While Philipp and I did some work on the DAS-protocol and its integration into Ruby, while working on openSNP, we didn’t really bother to make it reusable and instead solved the problem in a quick and dirty way, by just making it work with the internal database-models of openSNP. RubyDAS should one day get around this limitation and be a stand-alone gem which can be used to easily set up DAS-sources with Ruby. Right now you can use the code to set up simple annotation and reference servers. The code includes parsers for fasta and GFF files, so you can simply deliver DAS-conform sequences, as well as annotations for those sequences. Having said this: The project needs some more work. Not all DAS commands are implemented yet and up to now there hasn’t been a single test written. So if this project could be of use to you, you might need to invest some time and help us test the whole thing and implement the missing DAS-commands. So far RubyDAS uses http://bioruby.open-bio.org/ for the GFF and fasta-parsing, Sinatra for the webstuff and DataMapper as ORM.
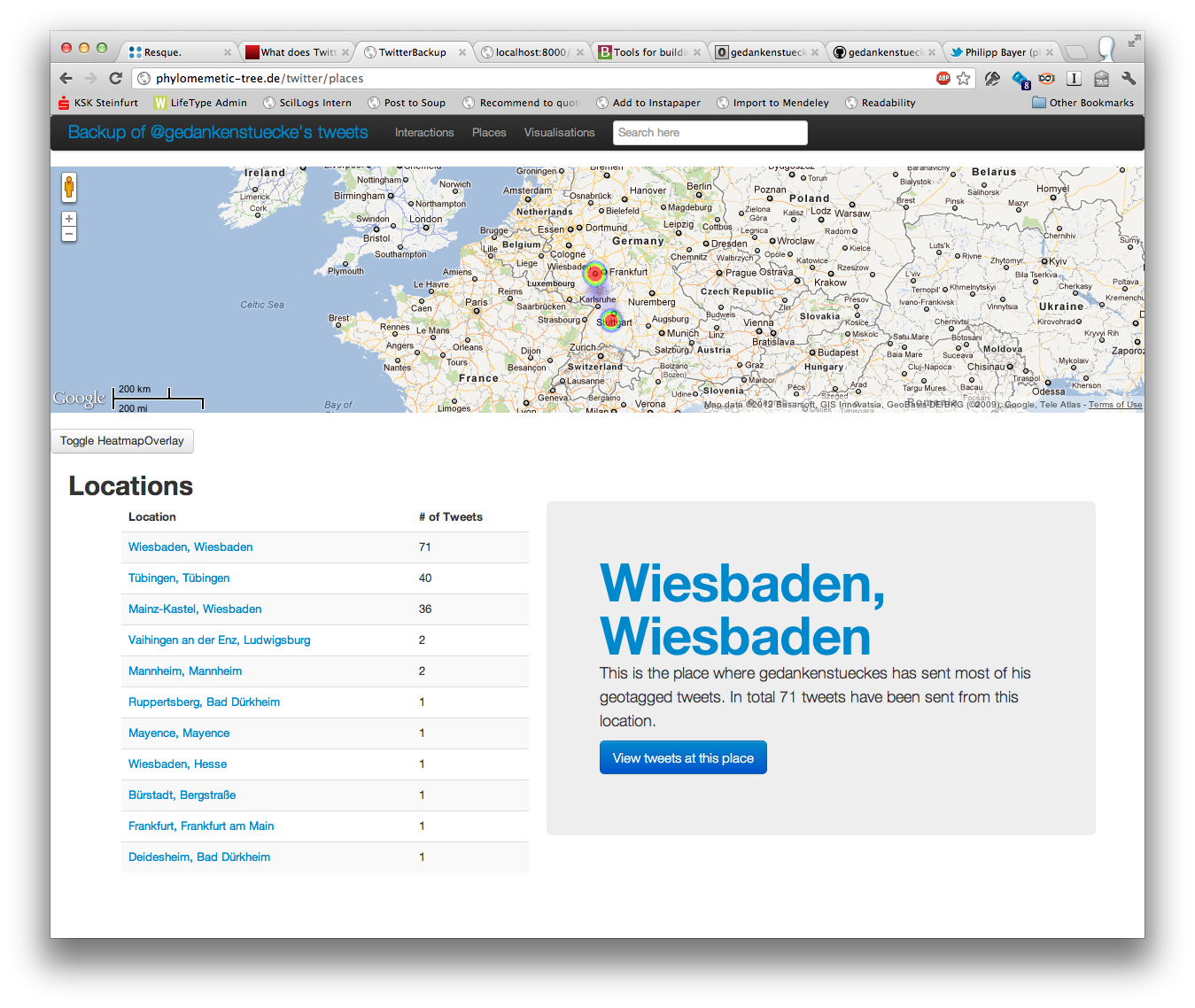
The second project which I started is a small, Rails-based, web-app to backup and visualize my own tweets. You can find the source code at GitHub in the twitter_backup-repository. As the search-feature of Twitter doesn’t allow you to search in old tweets and there is no way to scroll back in your own timeline this felt like a good idea. The tool grabs all my tweets and the retweets I’ve done and saves them locally. Using the web-frontend of twitter_backup you can scroll through your own timeline, see how much you interact with other users and find out on which days of the week and which times you most frequently tweet. Additionally the locations of your tweets are saved as well and you can find out from which places you most often tweet. And the biggest advantage of your own tweet-backup is also implemented: A working search-feature, which is done using Solr. You can search for users, specific dates or just the content of a tweet, which makes it much easier to find those interesting link you are sure you’ve tweeted but can’t find again on Twitter itself.
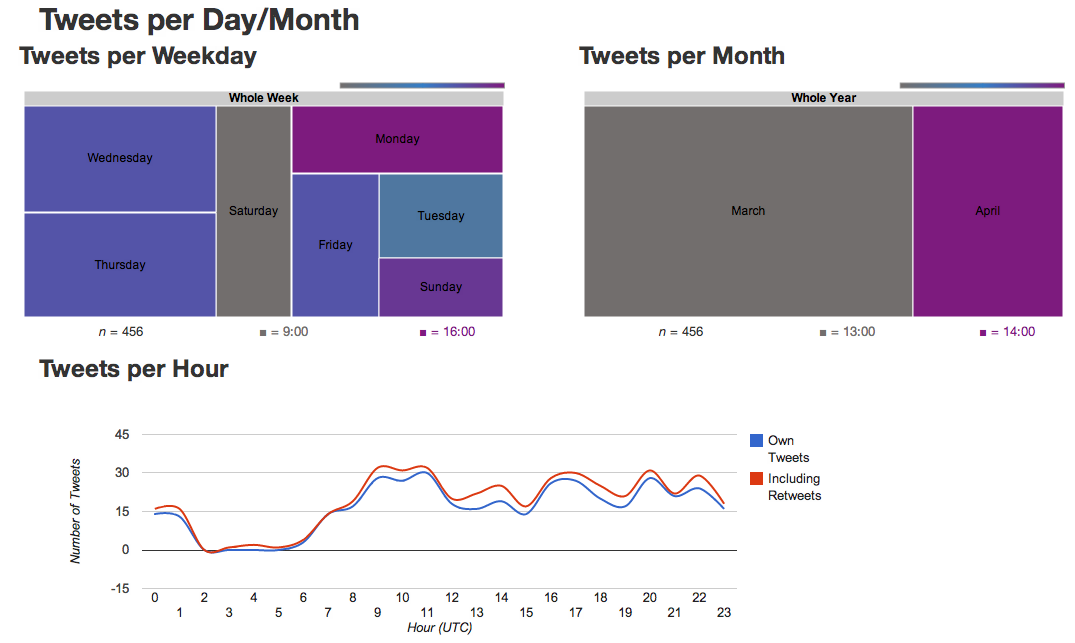
The general visualization is done using the Google Chart Tools and the mapping of the locations, along with the heat-maps are rendered through the Google Maps API and heatmap.js. If you’re interested in trying the small tool you can find my own setup on The Phylomemetic Tree.
